To do this we need to understand how the C compiler realize the two well known mechanisms: parameter passing by value and parameter passing by reference.
High-level languages have standard ways to pass data known as calling conventions. For high-level code to interface with assembly language, the assembly language code must use the same conventions as the high-level language. These conventions allow one to create subprograms that are re-entrant. A re-entrant subprogram may be called at any point of a program safely (even inside the subprogram itself). The major concern of these conventions is the description of the rules governing the use of the system stack. Before to call the function the caller program must "push" the parameters onto the stack in case of parameter passing by value or the parameter's address in case of passage by reference.
Let examine together the following C code example:
void f(char a, char b, char c)
{
char buffer1[6];
int d;
}
void main() {
function(1,2,3);
}
If we want to see how the C compiler implementthe function's parameter passing mechanisms in assembly language, there are two possibilities:
- Feed gcc with this code and the -S option, i.e. gcc -S example.c;
- Disassemble the executable produced by the compiler:
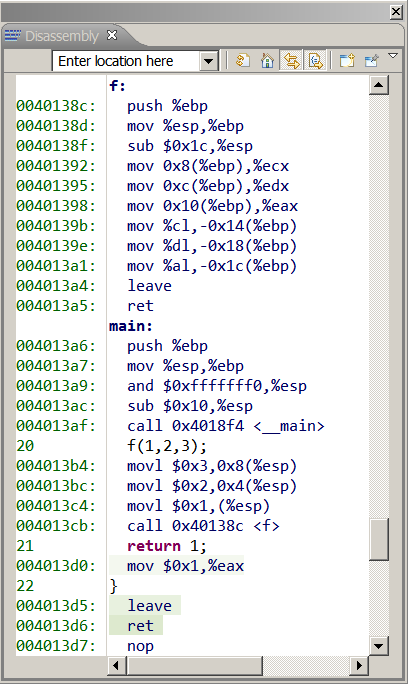
Here we can see that the caller program before to invoke the function f , pushes onto the stack the values of the three parameters:
004013b4: movl $0x3,0x8(%esp)
004013bc: movl $0x2,0x4(%esp)
004013c4: movl $0x1,(%esp)
004013cb: call 0x40138c <f>
Note that gcc, to speed up the things, prefers to use the movl instructions instead of the push ones to implement the push mechanism.
Anyway, what it really does is:

In case of parameters passed by reference, the caller program pushes the address of the variable instead of its content and the called routine access the address of the variable and can read and, eventually, modifies the content of the passed variables.
So far we saw how to deal with a void function, but what does it happen when we need to write a non void function?
The C calling conventions specify how this is done. Return values are passed via registers. All integral
types (char, int, enum, etc.) are returned in the EAX register. If they are smaller than 32-bits, they are extended to 32-bits when stored in EAX. (How they are extended depends on if they are signed or unsigned types.) 64-bit values are returned in the EDX:EAX register pair. Pointer values are also stored in EAX. Floating point values are stored in the ST0 register of the math co-processor.
The C calling conventions specify also that after the subprogram is over, the parameters that were pushed on the stack must be removed by the caller program. Other conventions are different. For example, the Pascal calling convention specifies that the subprogram must remove the parameters before returning to the caller program.
push 3;
push 2;
push 1;
call f;
So, the stack before the call of the function f, together with the memory layout of the executing process, is as depicted in the following figure:
Note that, depending on the implementation, the stack will either grow downward (towards lower memory addresses), or upward. In the case of the Intel, Motorola, SPARC and MIPS processors the stack grows downward. The stack pointer (SP) is also implementation dependent. It may point to the last address on the stack, or to the next free available address after the stack. In the case of Intel processors it points to the last address on the stack.
When the call instruction is executed to invoke the f function, the microprocessor save the
At the beginning of the f function, the EBP register is saved onto the stack and is used to save the current address of the top of the stack (ESP). Why? Because the C calling convention requires the value of EBX to be unmodified by the function call. If this is not done, it is very likely that the program will not work correctly. So the next two assembly instruction will surely be the standar prologue of our assembly routines skeleton linkable with C programs.
The answer is composed by several pieces:
Summing up all the previous quantities, we have 8+4+12+4=28 bytes. In this way, the compiler create a safe 28 bytes long stack frame to isolate the current contest of the function from the eventual new frame that , eventually, could be necessary to be implemented, for example, in case of calls to other function inside f o recursive calls of f. Puff... Puff...Puff.
This was a little boring! Wasn't it?
Anyway, lets try to summarize what we learned so far. The skeleton of our assembly routine callable from C program should be:
To understand how to access to the passed parameters we can look at how the compiler did it in our simple program:
It means that in our stack frame we have:
Location : data
f:0040138c: push %ebp
0040138d: mov %esp,%ebp
Note that it is mandatory, at the end of the procedure, to restore the original value of EBP and deallocate the local variables restoring the initial stack pointer ESP. This is done with the following two assembly statements that will be the standard epilogue of our function skeleton:
mov %ebp,%esp; deallocate locals
pop %ebp; restore original EBP value
Goinge back to our disassembly listing, we can see that the next instruction written by the compiler is:
0040138f: sub $0x1c,%espHere the compiler is making room in the stack for the function f local variables. This is done decreasing the stack pointer ESP of 0x1c (decimal 28). Remember that the stack grows toward low memory addresses. But. Hey, wait a moment! Why does the compiler reserve 28 bytes to make room for the two variables buffer1 and d that needs only: size(buffer1)+size(d)=6+4=10 bytes?
The answer is composed by several pieces:
- First of all, we must remember that memory can only be addressed in multiples of the word size. A word in our case is 4 bytes, or 32 bits. So our 6 byte buffer needs two words to be stored, that is 8 bytes instead of 6!
- Then, we have to reserve room for d, that is one word or 4 bytes.
- Then, the compiler want to reserve rooms to make a copy of the function parameters. There are three char parameters, but for each char variables we have to use 1 word. So we have 12 bytes for the parameters.
- Finally, we must take into account that we pushed onto the stack the 4 bytes EBP register and this account for 4 bytes more .
Summing up all the previous quantities, we have 8+4+12+4=28 bytes. In this way, the compiler create a safe 28 bytes long stack frame to isolate the current contest of the function from the eventual new frame that , eventually, could be necessary to be implemented, for example, in case of calls to other function inside f o recursive calls of f. Puff... Puff...Puff.
This was a little boring! Wasn't it?
Anyway, lets try to summarize what we learned so far. The skeleton of our assembly routine callable from C program should be:
subprogram_label:
push %ebp
mov %esp,%ebp
sub SZ,%esp ; SZ=# bytes needed by local variables
; subprogram code
mov %ebp,%esp
push %ebp
ret
Note that the prologue and epilogue of a subprogram can be simplified by using two special instructions that are designed specifically for this purpose. The ENTER instruction performs the prologue code and the LEAVE performs the epilogue. The ENTER instruction takes two immediate operands. For the C calling convention, the second operand is always 0. The first operand is the number bytes needed by local variables. The LEAVE instruction has no operands.
To understand how to access to the passed parameters we can look at how the compiler did it in our simple program:
mov 0x8(%ebp),%ecx ; move the value of a in ecx
mov 0xc(%ebp),%edx ; move the value of b in edx
mov 0x10(%ebp),%eax ; move the value of a in eax
It means that in our stack frame we have:
Location : data
EBP + 0x10 : content of c
EBP + 0xc : content of b
EBP + 0x8 : content of a
EBP + 4 : Return address
EBP : saved EBP
In case of parameters passed by reference, the caller program pushes the address of the variable instead of its content and the called routine access the address of the variable and can read and, eventually, modifies the content of the passed variables.
So far we saw how to deal with a void function, but what does it happen when we need to write a non void function?
The C calling conventions specify how this is done. Return values are passed via registers. All integral
types (char, int, enum, etc.) are returned in the EAX register. If they are smaller than 32-bits, they are extended to 32-bits when stored in EAX. (How they are extended depends on if they are signed or unsigned types.) 64-bit values are returned in the EDX:EAX register pair. Pointer values are also stored in EAX. Floating point values are stored in the ST0 register of the math co-processor.
The C calling conventions specify also that after the subprogram is over, the parameters that were pushed on the stack must be removed by the caller program. Other conventions are different. For example, the Pascal calling convention specifies that the subprogram must remove the parameters before returning to the caller program.










