As a programmer or analyst-programmer, understanding stack/buffer overflow, and knowing how to find and mitigate it, is useful, at least, in two circumstances:
- when you are debugging a piece of code, dealing with unpredictable run time behaviors. In this case, it is highly probable that, you are facing a buffer overflow problem and you have to find it. Soon!
- when you are working on a software of which buffer overflow flaws could be eventually exploited in order to damage you, your organizations or your customers.
In this post I'd like to focus on the first topic.
Let start having a look at a simple C program with a simple buffer overflow.
#include
int main(void){
char c[4] = { 'A', 'B', 'C', 'D' };
char d[4] = { 'W', 'X', 'Y', 'Z' };
printf("c[0] is '%c'\n", c[0]);
d[4] = 'Z';
printf("c[0] is '%c'\n", c[0]);
return 0;
}
Most of us, looking at the previous code would think that the output should be:
c[0] is 'A'
c[0] is 'A'
Are we sure? Lets compile, link and execute it! Drum Roll, please. The output is:
What happened here? After the first printf, the statement
d[4] = 'Z'; put the character
'Z' in the fifth position of the char array
d. But. wait a moment, d is a 4 elements array. How is it possible to write beyond the limits of the array and, why didn't the C compiler warn us about it? To understand this, I'd suggest to check the following link for a discussion on this topic:
Why do compilers not warn about out-of-bounds static array indices?. If you don't have time or you don't want to leave me alone to go there :), to make it short, in C there is no strict buffer checking in order to produce lighter and faster code then other programming language. There is another question that need to be answered:
Where the hell did the statement "
d[4] = 'Z';" write the
'Z' character? Well, apparently, it went in the first position of the c array. How is it possible?
When the compiler read the two declaration:
char d[4] = { 'W', 'X', 'Y', 'Z' };
it reserves enough contiguous space in the program stack to store the c and d array.
Compiling the code with gcc -S or using a smart :) IDE like Eclipse, we can have a look at the corresponding assembly code. Here I copied it for you from the Eclipse's disassembly window:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
main:
push %ebp
mov %esp,%ebp
and $0xfffffff0,%esp
sub $0x20,%esp
call 0x401918 <__main>
char c[4] = { 'A', 'B', 'C', 'D' };
movb $0x41,0x1c(%esp)
movb $0x42,0x1d(%esp)
movb $0x43,0x1e(%esp)
movb $0x44,0x1f(%esp)
char d[4] = { 'W', 'X', 'Y', 'Z' };
movb $0x57,0x18(%esp)
movb $0x58,0x19(%esp)
movb $0x59,0x1a(%esp)
movb $0x5a,0x1b(%esp)
printf("c[0] is '%c'\n", c[0]);
mov 0x1c(%esp),%al
movsbl %al,%eax
mov %eax,0x4(%esp)
movl $0x403064,(%esp)
call 0x401b50 <printf>
d[4] = 'Z';
movb $0x5a,0x1c(%esp)
printf("c[0] is '%c'\n", c[0]);
|
In particular, gcc reserves 0x20 (32 in decimal) bytes for the main local data at line 5. You are authorized to ask why 32 bytes and not 4 bytes (one for each char of c) + 4 bytes (one for each char of d) = 8 bytes. You can ask. But, answering it would bring us too far and it is not strictly important to understand this example. If there will be any request about it we play with it and understand why does it happen :). |
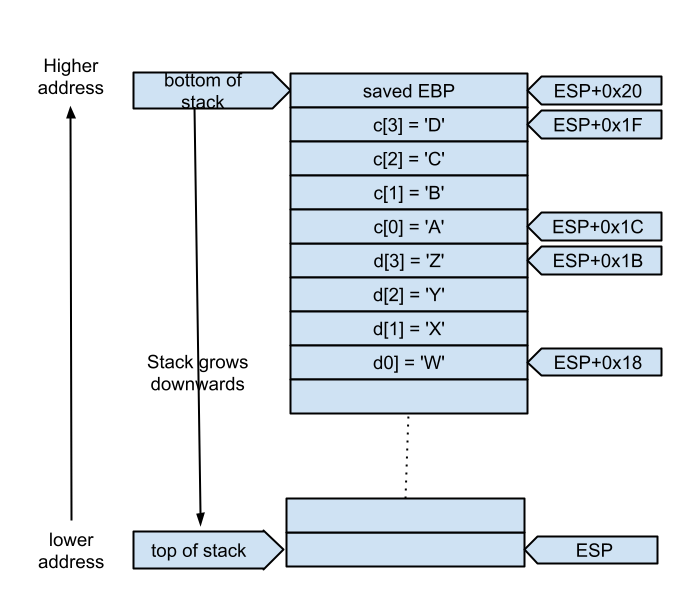
Taking into account that
0x41 is the ASCII code for
'A', we can easily recognize the assembly statements that initialize the arrays c (line 8 to 11) and d (line 13 to 16).
As for up to line 16, the stack content can be represented as in the figure on the right.
Then, the instruction
d[4] = 'Z'; is executed and, without any warning, the code smashes the d array and put 'Z' ASCII code in the memory location
+0x1C, that is the memory location where c[1] is stored.
So the following printf correctly print the content of
c[1], that is
'Z' and not
'A' as expected.
What should we do to avoid buffer overflow? Add code to check array boundary! And, when you are debugging programs with an apparent unpredictable behavior, check all the statements assigning value to arrays elements.
In the second part of this post we'll try to understand together how buffer overflow can be a potential security vulnerability.

